How-to Guide: Correlations
Dans le fichier cc_tk.feature.correlation, 3 méthodes de sélection de variables à partir des corrélations sont implémentées. Ces 3 méthodes sont implémentées au travers de l’interface TransformerMixin de sklearn pour pouvoir être intégrée facilement dans des pipelines.
Corrélation avec la variable cible (
CorrelationToTarget) : on garde uniquement les variables qui sont corrélées avec la variable à prédire. Le seuil de corrélation est un paramètre de ce transformer.Détection des corrélations par paires (
PairwiseCorrelationDrop) : quand une variable est corrélée (seuil de corrélation en paramètre), on retire cette variable de notre sélection. Par symétrie, on devrait retirer les deux variables en questions, le choix qui est fait est de retirer celle qui est en moyenne la plus corrélée avec les autres variables. Cette méthode est expliquée ici et étendue pour éviter de retirer trop de colonnes. L’extension repose sur le fait que l’on retire itérativement les variables corrélées pour éviter de les prendre en compte lorsque l’on s’intéresse aux variables suivantes.Regroupement de variables en fonction de leurs corrélations (
ClusteringCorrelation) : les variables sont regroupés par une CAH en prenant comme distance $1-abs(corr(X_i, X_j))$. Les groupes sont déterminés par un seuil de corrélation, toutes les variables dans un groupe sont corrélées à plus de $1 - seuil$. La méthode est détaillée ici. Pour chaque groupe, 2 possibilités : on garde un nombre de colonnes fixé à l’avance (1 par défaut), on construit une PCA pour chaque groupe et on choisit le nombre de composantes à garder.
import pandas as pd
import matplotlib.pyplot as plt
from sklearn import set_config
from sklearn.datasets import load_diabetes
from sklearn.pipeline import make_pipeline
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from sklearn.linear_model import LinearRegression
from sklearn.dummy import DummyRegressor
from cc_tk.feature.correlation import (
CorrelationToTarget,
ClusteringCorrelation,
PairwiseCorrelationDrop,
)
set_config(transform_output="pandas")
X, y = load_diabetes(return_X_y=True, as_frame=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=22)
X.columns
Index(['age', 'sex', 'bmi', 'bp', 's1', 's2', 's3', 's4', 's5', 's6'], dtype='object')
baseline = DummyRegressor()
baseline.fit(X_train, y_train)
baseline.score(X_test, y_test)
-0.0003801753238461547
Corrélation avec la cible
correlation_target_pipeline = make_pipeline(
MinMaxScaler().set_output(transform="pandas"),
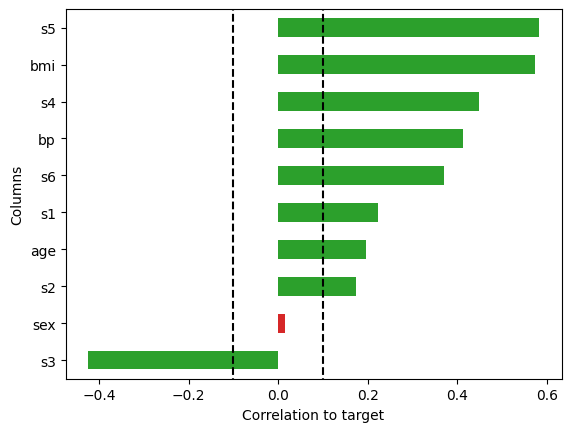
CorrelationToTarget(threshold=0.1),
LinearRegression(),
)
correlation_target_pipeline.fit(X_train, y_train)
correlation_target_pipeline.score(X_test, y_test)
0.48613757778290945
correlation_target_pipeline["correlationtotarget"]._selected_columns
Index(['age', 'bmi', 'bp', 's1', 's2', 's3', 's4', 's5', 's6'], dtype='object')
correlation_target_pipeline["correlationtotarget"].plot_correlation()
Corrélation par pair
correlation_pairwise_pipeline = make_pipeline(
MinMaxScaler().set_output(transform="pandas"),
PairwiseCorrelationDrop(threshold=0.8),
LinearRegression(),
)
correlation_pairwise_pipeline.fit(X_train, y_train)
correlation_pairwise_pipeline.score(X_test, y_test)
0.4686082298436729
correlation_pairwise_pipeline["pairwisecorrelationdrop"]._columns_selection
Index(['age', 'sex', 'bmi', 'bp', 's2', 's3', 's4', 's5', 's6'], dtype='object')
Clusters de corrélation
Il y a deux summary_method disponibles:
la valeur par défaut
firstqui utilise uniquement les premières variables de chaque cluster. On peut voir les variables retenues avec l’attribut_selected_columns_pcaqui utilise l’analyse en composantes principales pour résumer les clusters. On peut voir les colonnes en output avec l’attribut_output_columns
correlation_clustering_pipeline = make_pipeline(
MinMaxScaler().set_output(transform="pandas"),
ClusteringCorrelation(threshold=0.8, summary_method="pca", n_variables_by_cluster=2),
LinearRegression(),
)
correlation_clustering_pipeline.fit(X_train, y_train)
correlation_clustering_pipeline.score(X_test, y_test)
0.3989807732731533
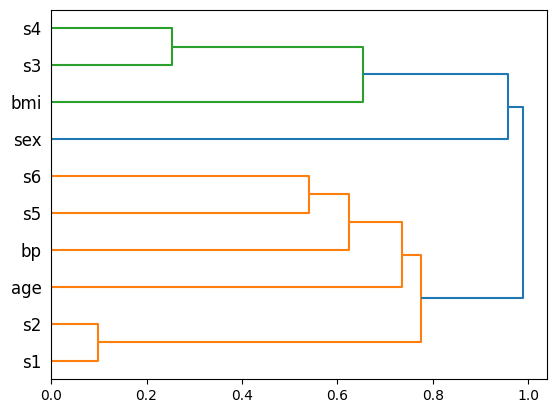
dendro = correlation_clustering_pipeline["clusteringcorrelation"].plot_dendro()
correlation_clustering_pipeline["clusteringcorrelation"]._output_columns
# correlation_clustering_pipeline["clusteringcorrelation"]._selected_columns_ # When summary_method="first"
[['age-bp-s1-s2-s5-s6 0', 'age-bp-s1-s2-s5-s6 1'],
['sex 0'],
['bmi-s3-s4 0', 'bmi-s3-s4 1']]
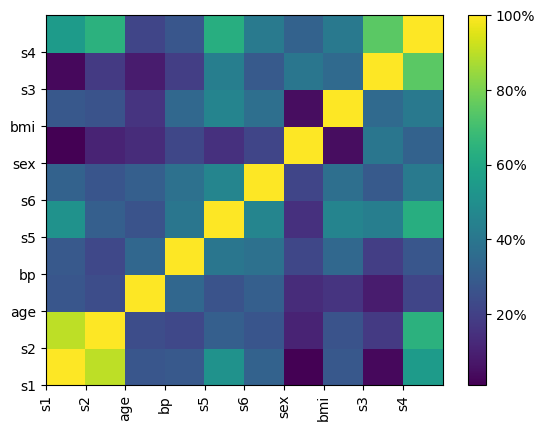
correlation_clustering_pipeline[
"clusteringcorrelation"
].plot_correlation_matrix()
<Axes: >
Combinaison de différents transformer
Il est aussi possible de combiner différentes méthodes de sélection de variables.
correlation_combined_pipeline = make_pipeline(
MinMaxScaler().set_output(transform="pandas"),
CorrelationToTarget(threshold=0.1),
ClusteringCorrelation(threshold=0.3, summary_method="first"),
LinearRegression(),
)
correlation_combined_pipeline.fit(X_train, y_train)
correlation_combined_pipeline.score(X_test, y_test)
0.48114472598560776